How the data is organized physically on disk deeply impacts these calculations, as it materially affects how expensive (or inexpensive) index access will be. Suppose you have a table where the rows have a primary key populated by a sequence. As data is added to the table, rows with sequential sequence numbers might be, in general, next to each other.
Note The use of features such as ASSM or multiple FREELIST/FREELIST GROUPS will affect how the data is organized on disk. Those features tend to spread the data out, and this natural clustering by primary key may not be observed.
The table is naturally clustered in order by the primary key (since the data is added in more or less that order). It will not be strictly clustered in order by the key, of course (we would have to use an IOT to achieve that); in general, rows with primary keys that are close in value will be close together in physical proximity.
When you issue the query the rows you want are typically located on the same blocks. In this case, an index range scan may be useful even if it accesses a large percentage of rows, simply because the database blocks that we need to read and reread will most likely be cached since the data is colocated. On the other hand, if the rows are not colocated, using that same index may be disastrous for performance. A small demonstration will drive this fact home. We’ll start with a table that is pretty much ordered by its primary key: SQL> create table colocated ( x int, y varchar2(80) ); Table created. SQL> beginfor i in 1 .. 100000loopinsert into colocated(x,y) values (i, rpad(dbms_random.random,75,’*’) ); end loop;end;/
This table fits the description we laid out earlier with about 100 rows/block in an 8KB database. In this table, there is a very good chance that the rows with X=1, 2, 3 are on the same block. Now, we’ll take this table and purposely “disorganize” it. In the COLOCATED table, we created the Y column with a leading random number, and we’ll use that fact to disorganize the data so that it will definitely not be ordered by primary key anymore:
Arguably, these are the same tables—it is a relational database, so physical organization has no bearing on the answers returned (at least that’s what they teach in theoretical database courses). In fact, the performance characteristics of these two tables are as different as night and day, while the answers returned are identical. Given the same exact question, using the same exact query plans, and reviewing the TKPROF (SQL Trace) output, we see the following: select * from colocated where x between 20000 and 40000
Note I ran each query five times in order to get a good average runtime for each (hence, the TKPROF output shows 100,000+ rows processed).
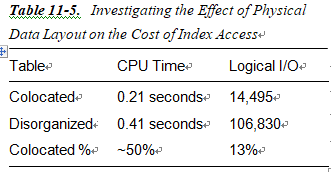
I think this is pretty incredible. What a difference physical data layout can make! Table 11-5 summarizes the results.
Table 11-5. Investigating the Effect of Physical Data Layout on the Cost of Index Access Table CPU Time Logical I/O Colocated 0.21 seconds 14,495 Disorganized 0.41 seconds 106,830 Colocated % ~50% 13%
In my database using an 8KB block size, these tables had the following number of total blocks apiece:
The query against the disorganized table bears out the simple math we did earlier: we did 20,000+ logical I/Os (100,000 total blocks queried and five runs of the query). We processed each and every block 20 times! On the other hand, the physically COLOCATED data took the logical I/Os way down. Here is the perfect illustration of why rules of thumb are so hard to provide—in one case, using the index works great, and in the other it doesn’t. Consider this the next time you dump data from your production system and load it into development, as it may very well provide at least part of the answer to the question, “Why is it running differently on this machine—aren’t they identical?” They are not identical.
Note Recall from Chapter 6 that increased logical I/O is the tip of the iceberg here. Each logical I/O involves one or more latches into the buffer cache. In a multiuser/CPU situation, the CPU used by the second query would have undoubtedly gone up many times faster than the first as we spin and wait for latches. The second example query not only performs more work but also will not scale as well as the first.

Leave a Reply